Data Structure / Algorithm - Array / List / Map
Array / List / Map에 관해 설명 및 차이점
Array - array<>와 vector<>
: 인덱스를 통해 원소에 접근할 수 있는 데이터 시퀀스 컨테이너. 모든 요소에 Random Acces 방식으로 접근하기 때문에 ‘빠른 데이터 검색’이 가능하다. (시간 복잡도 O(N))
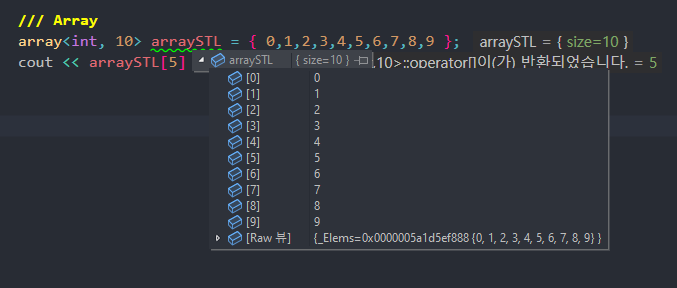
-> array<> STL은 ‘고정 크기 배열’로 컴파일 시점에 크기가 결정되며, 크기가 변경되지 않는다.
-> array<>는 기본적인 배열 인터페이스로 배열의 요소에 접근한다.
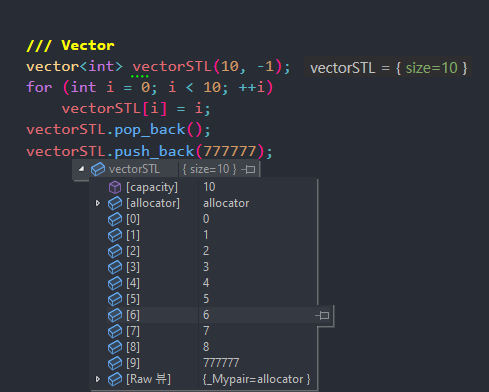
-> vector<> STL은 ‘힙 메모리’에 할당되는 동적 배열로, 배열의 크기가 변할 수 있다. 하지만 크기가 변경될 때, 메모리를 재할당하기 때문에 약간의 오버헤드가 존재한다.
-> vector<>는 push_back, pop_back과 같은 요소 추가 및 제거 기능, capacity, size의 크기 관리 기능을 제공한다.
List
: 각 요소는 다음 데이터 요소를 가리키는 Pointer를 가지고 있는 시퀀스 컨테이너.
다음 요소 뿐만 아니라 이전 요소도 가리키는 List를 ‘이중 연결 리스트’라고 하며 양방향 연결된 요소를 가리키는 double linked 방식으로 ‘빠른 데이터의 삽입 / 삭제’가 가능하다. (검색 시 순차탐색으로 시간 복잡도 O(N))
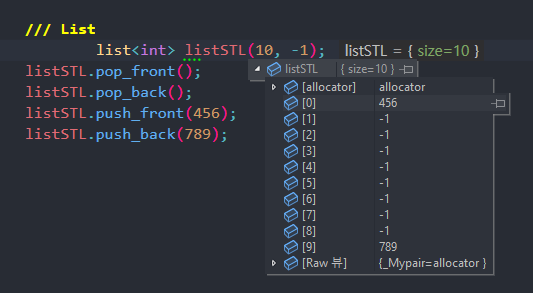
-> 요소에 대한 임의 엑세스 (Random Access)는 거의 발생하지 않으며, 요소 삽입 / 삭제를 앞, 뒤, 중간 등 빈번하게 사용해야 하는 경우에 사용한다.
Map
: 각 요소가 데이터의 Key와 Value의 쌍으로 이루어져 데이터를 효율적으로 관리하고 검색할 수 있다. Key는 단 하나만 존재하며 고유하고, Key를 가지고 데이터를 자동으로 정렬해 준다.
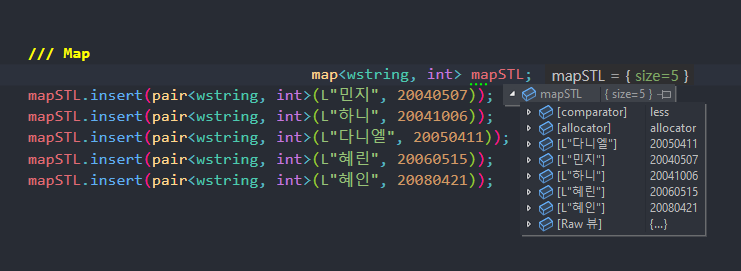
-> Key값인 자료형 wstring의 이름들에 따라 자동정렬된 것을 볼 수 있다.
-> map은 특정 원소를 검색, 삽입, 삭제할 때 평균적으로 O(logN)의 시간 복잡도를 가진다.
Map의
Key값은 중복될 수 없는데, “중복을 허용하려면” multimap<>을 사용해야 한다.
또한 Map은Key에 “따라 자동정렬이 되는데, “자동정렬을 원치 않는다면” unorderedmap<>(해시테이블)을 사용해야 한다
댓글남기기